

DeepSeek-V4发布,华为昇腾超节点深度适配!
4月24日上午,没有预热、没有直播、没有CEO站台演讲。
DeepSeek-V4预览版悄然上线,同步开源,同步官网,同步API。
近60页的技术报告全文公开,坦率得令人震惊,
它不仅揭开了V4延迟发布的秘密,更展现了DeepSeek近乎残酷的工程理性。
也让更多人看到了:中国AI,正在走出一条从未有人走过的路。

01
百万上下文,从“王牌”变“标配”
先看最核心的数字。
V4分两个版本:Pro(1.6T参数)和Flash(284B参数)。

一年前,百万窗口还是Google Gemini的独家王牌。
其他所有模型,闭源的开源的,要么128K要么200K,没人敢碰这个量级。
因为Transformer自注意力的计算复杂度随上下文长度平方级增长——窗口翻倍,算力变四倍。
这是个结构性的物理天花板。
DeepSeek如何破局?
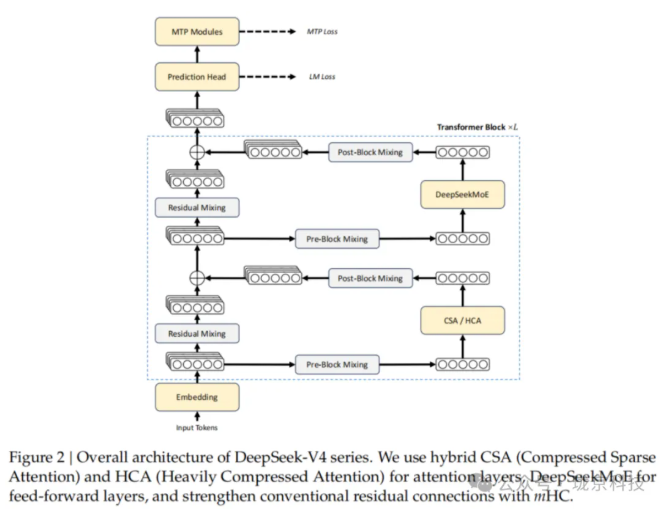
答案是DSA(DeepSeek Sparse Attention),加上一套全新的混合注意力架构CSA+HCA。
通俗地说,就是你读一本1000页的书,想找出“第500页的观点和哪些内容相关”。
笨办法是把第500页和其他999页逐一比对,页数翻倍工作量变四倍。
聪明办法是先粗筛一遍,判断哪些页面可能相关,只精读那几十页,其余直接跳过;
然后精读的时候也不逐字看,先读摘要。
两步叠加,工作量就压下来了。
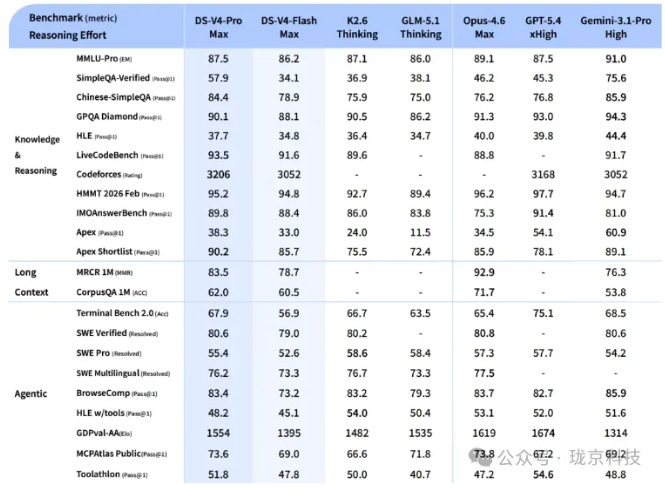
效果呢?
在100万token场景下,V4的单token推理计算量只有前代V3.2的27%,显存占用压到只有10%。
换算过来,同等算力下能服务的并发量是原来的3到4倍。
这就是一个工程奇迹,而且关键是——他们开源了。
这意味着,任何一个团队、任何一家公司,都可以在这个架构上接着迭代。
你可能已经知道V4很强,但你可能不知道它为什么让我们等了这么久。
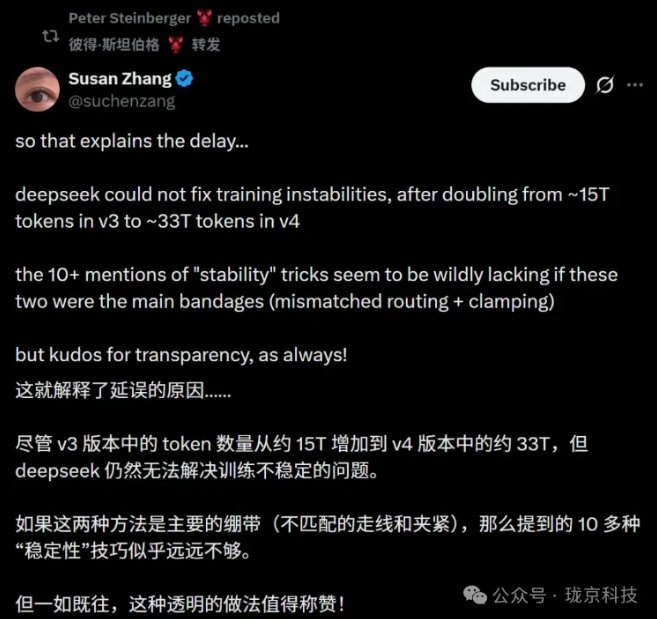
从V3到V4,DeepSeek 的研发周期是484天,比上一代多了近一倍。
技术报告里没有明说原因,但“稳定性”这个词,却史无前例地出现了10余次。
真相是什么?这是在万亿参数规模上,一场与硬件、编译器和数学极限的三方博弈。
DeepSeek 没有回避任何困难,如谷歌DeepMind研究员所评价:“这种透明的做法值得称赞。”
02
DeepSeek V4首发适配华为昇腾
如果你只看到了模型性能,那可能错过了最重要的一行小字。
V4的发布稿末尾,悄然带过一句话:“下半年批量上华为算力。”
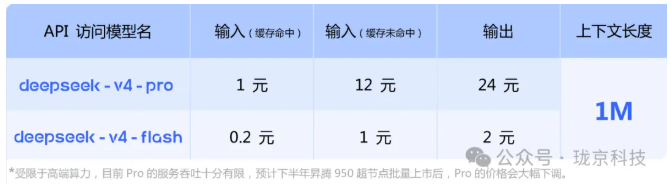
DeepSeek表示,受限于高端算力,目前DeepSeek-V4-Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
DeepSeek罕见地将华为昇腾和英伟达共同写进DeepSeek-V4技术报告:“我们在英伟达GPU和华为昇腾NPU平台上验证了细粒度EP(专家并行)方案。”

V4发布后,华为昇腾也同步宣布“超节点全系列产品支持DeepSeek-V4系列模型”。
昨天,华为昇腾团队直接上线开播,证明了两件事,
第一,DeepSeek V4确实能在昇腾上跑起来,不是PPT发布,是真实部署。
第二,不仅跑得通,还能优化得很好,直播中展示了推理延迟等关键性能指标,这意味着从底层算子到上层框架的适配已进入可用阶段。

百万token的上下文窗口,被DeepSeek做成了所有服务的标配。
这种技术底气,需要同样强悍的算力底座来承载。
而那底座,正是昇腾950超节点。
昇腾950超节点所搭载的Atlas 350加速卡,规格相当硬核:

这些参数直指一个目标:让千亿甚至万亿参数的大模型,在多卡集群上高效运行。
直播中给出了官方实测数据,答案非常清晰:
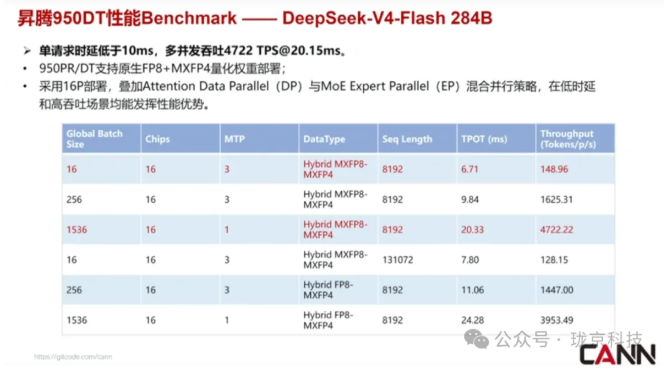
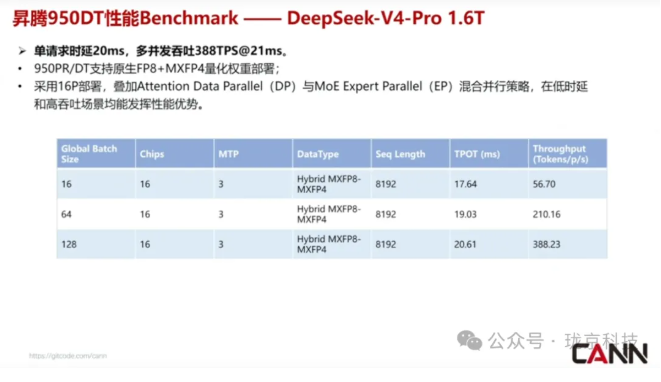
这意味着什么?
意味着部署门槛断崖式下降。
推理成本的大幅降低,将直接推动大模型应用在千行百业的真正落地。
写在最后,
从坦诚到近乎残酷的技术报告,到与华为昇腾算力握手,
DeepSeek 正在用行动写下自己的座右铭:“不诱于誉,不恐于诽,率道而行,端然正己。”
他们不掩饰在万亿参数无人区摸索时的狼狈,
不夸大自己与世界最强的差距,也不掩盖为追求极致效率所付出的代价。
与此同时,他们将最先进的模型,跑在了中国自己的算力底座之上。
一个真正“自主可控”的 AI 时代,正在加速到来。
后续我们还会持续跟进DeepSeek V4与昇腾950的最新进展,欢迎保持关注。


